Hola de nuevo a todos, hoy os traigo el penúltimo tema de la asignatura.
 |
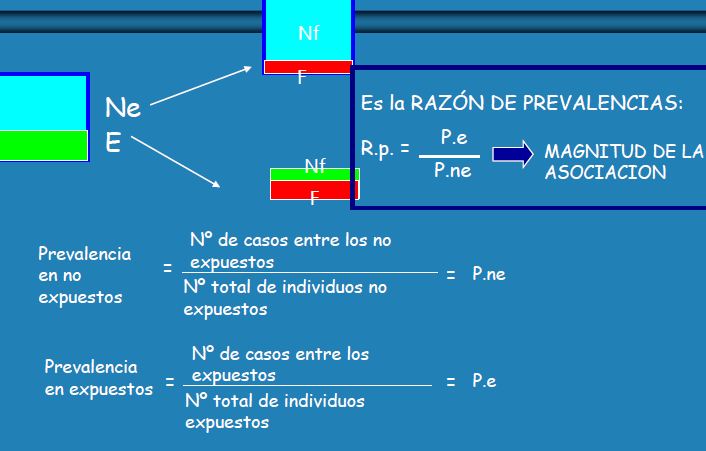
Inferencia estadística
- Población de estudio: conjunto de pacientes sobre los que queremos estudiar alguna cuestión
- Muestra: conjunto de individuos concretos que participan en el estudio
- Tamaño muestral: número de individuos de la muestra
Y la inferencia estadística es el conjunto de procedimientos que permite pasar de lo particular (muestra) a lo general (población).
- Técnicas de muestreo: procedimientos que permiten elegir muestras de tal forma que éstas reflejen las características de la población
Cuando trabajamos con muestras, siempre hay que asumir un cierto error, si la muestra se elige al azar, se puede evaluar ese error y la técnica de muestreo se denomina muestreo probabilístico o aleatorio, y el error asociado a esa muestra elegida al azar se llama error aleatorio.
Error estándar
Medida que trata de captar la variabilidad de los valores del estimador, el error estándar de cualquier estimador mide el grado de variabilidad en los valores del estimador en las distintas muestras de un determinado tamaño que pudiésemos tomar de una población. Para calcular el error estándar:
Este dependerá de cada estimador, y mientras mayor sea el tamaño de una muestra, menor será el error estándar:

Error estándar para una media
Error estándar para una proporción
Teorema central del límite
Para estimadores que pueden ser expresados como suma de valores muestrales, la distribución de sus valores sigue una distribución normal con media de la de la población y desviación típica igual al error estándar del estimador de que se trate.

Intervalos de confianza
Forma de conocer el parámetro en una población midiendo el error que tiene que ver con el azar, se calcula considerando que el estimador muestral sigue una distribución normal, como establece la teoría central del límite.
Cálculo:
⤱ Para nivel de confianza 95%, z=1,96
⤱ Para nivel de confianza 99%, z=2,58
Mientras mayor sea la confianza que queremos otorgar al intervalo, éste será más amplio y el intervalo menos preciso. Podemos calcular intervalos de confianza para cualquier parámetro.
Tipos de muestreo
- Muestreo probabilístico (aleatorio): elementos que tienen la misma probabilidad de ver elegidos. Método que consiste en extraer una parte de una población, de manera que todas las muestras posibles de tamaño fijo tengan la misma probabilidad de ser seleccionadas. Hay diferentes tipos dentro de este grupo:
- aleatorio simple: cada unidad tiene la probabilidad equitativa de ser incluida en la muestra. Tenemos de sorteo o rifa (no puede usarse cuando el universo es grande) y tabla de números aleatorios (económico y requiere menos tiempo)
- sistemático: cada unidad del universo tiene la misma probabilidad de ser seleccionada
- estratificado: subdivisión de la población en subgrupos, porque las variables principales que deben someterse a estudio presentan cierta variabilidad o distribución conocida que puede afectar los resultados
- conglomerado: en la selección de muestra se toman los subgrupos o conjuntos de unidades "conglomerados" y en este muestreo el investigador no conoce la distribución de la variable
- Muestreo no probabilístico: no sigue el proceso aleatorio, el investigador selecciona la muestra siguiendo algunos criterios identificados para los fines del estudio que realiza. Tenemos tres tipos:
- por conveniencia o intencional: el investigador decide que elementos integrarán la muestra
- por cuotas: el investigador selecciona la muestra considerando algunas variables a estudiar (sexo, religión,raza...)
- accidental: se usa para el estudio las personas disponibles en un momento dado, según lo que interesa estudiar
Tamaño de la muestra
Este tamaño dependerá de el error estándar, de la mínima diferencia entre los grupos de comparación que se considera importante en los valores de la variable a estudiar, de la variabilidad de la variable a estudiar y del tamaño de la población de estudio.